RL Bipedal Locomotion System
A semi-autonomous research platform for bench-testing reinforcement learning techniques on a 31-DOF physics-based humanoid - built from scratch, trained in parallel, monitored remotely.
What began as a desire to control a simulated walking biped with my keyboard turned into:
- creating an anatomically correct biped rig
- building a custom remote-supervised research platform
- a new quest to push the bleeding edge of RL
- a humbling ponderance of the philosophy behind what general intelligence really is.
The Platform
This isn't just a trained biped - it's a research platform for rapidly testing RL techniques against physics-based locomotion.
The pipeline ingests ideas from recent arxiv papers - reward shaping strategies, curriculum designs, policy architectures - and lets me deploy them against a custom biped rig running in 256 parallel environments. Each training run is monitored remotely via a live dashboard, with TensorBoard tracking every metric that matters.
The core loop: read a paper > implement the technique > train 256 bipeds in parallel > watch the results live > iterate.
How It Works
Godot 4.5 runs 256 parallel physics simulations at 8x time acceleration while Python/PyTorch trains a dual-network PPO policy (actor + critic). The biped learns through progressive curriculum - belt speed ramps, harness force decay, direction constraints - bridging the gap from standing to walking without scripted motion.
Building the biped rig
The Biped
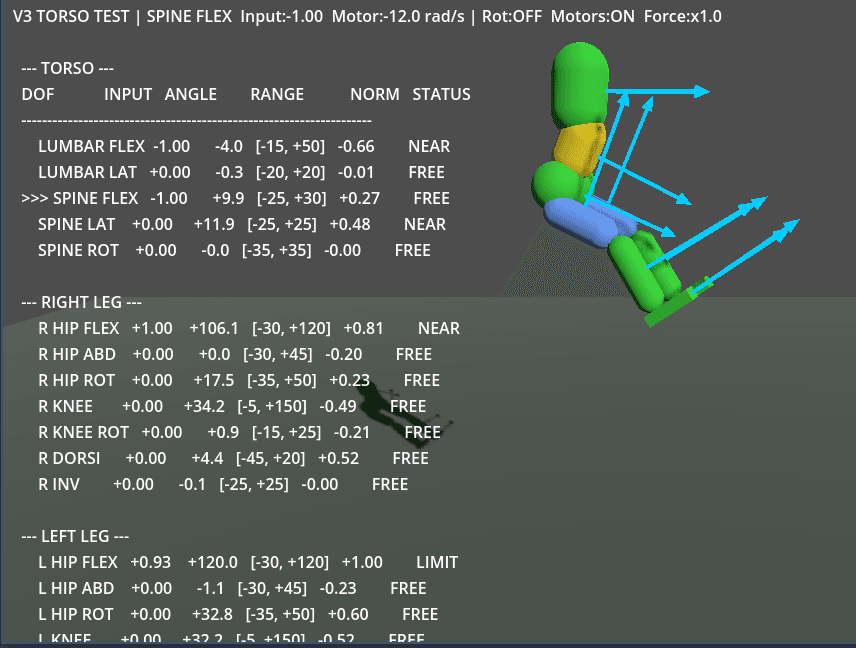
Before any training could happen, the humanoid itself had to be built from scratch - limb by limb, joint by joint.
31 degrees of freedom:
- Legs (14 DOF): Hip flexion, abduction, and rotation; knee flexion and rotation; ankle dorsiflexion and inversion - per leg. Each joint constrained to its real-world range of motion.
- Torso (5 DOF): Lumbar and spine flexion/lateral bend, spine rotation. Added after discovering that a locked torso acts as destabilizing dead weight during stepping.
- Arms (12 DOF): Shoulders, elbows, forearms, wrists. Currently held at sides with angular damping; future phases unlock them for combat.
Every bone segment was hand-modeled in Godot with anatomically accurate proportions. Knees only flex in one axis. Hips get their full ball-and-socket range. If a joint can hyperextend or rotate impossibly, the RL policy will find and exploit it - so the skeleton has to move like a real one.
The pull-up test became the go-to sanity check - hang the biped from a bar and verify that every joint bends correctly under load, with no clipping, no impossible angles, and no joints fighting each other.
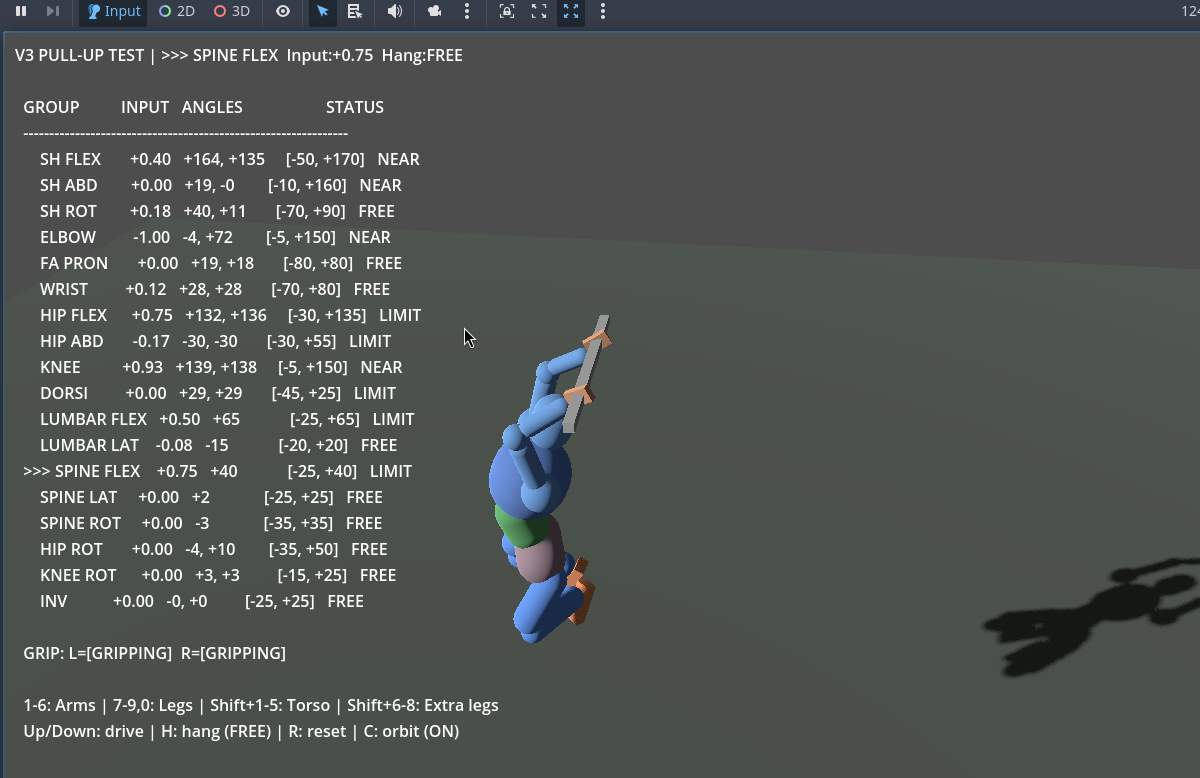
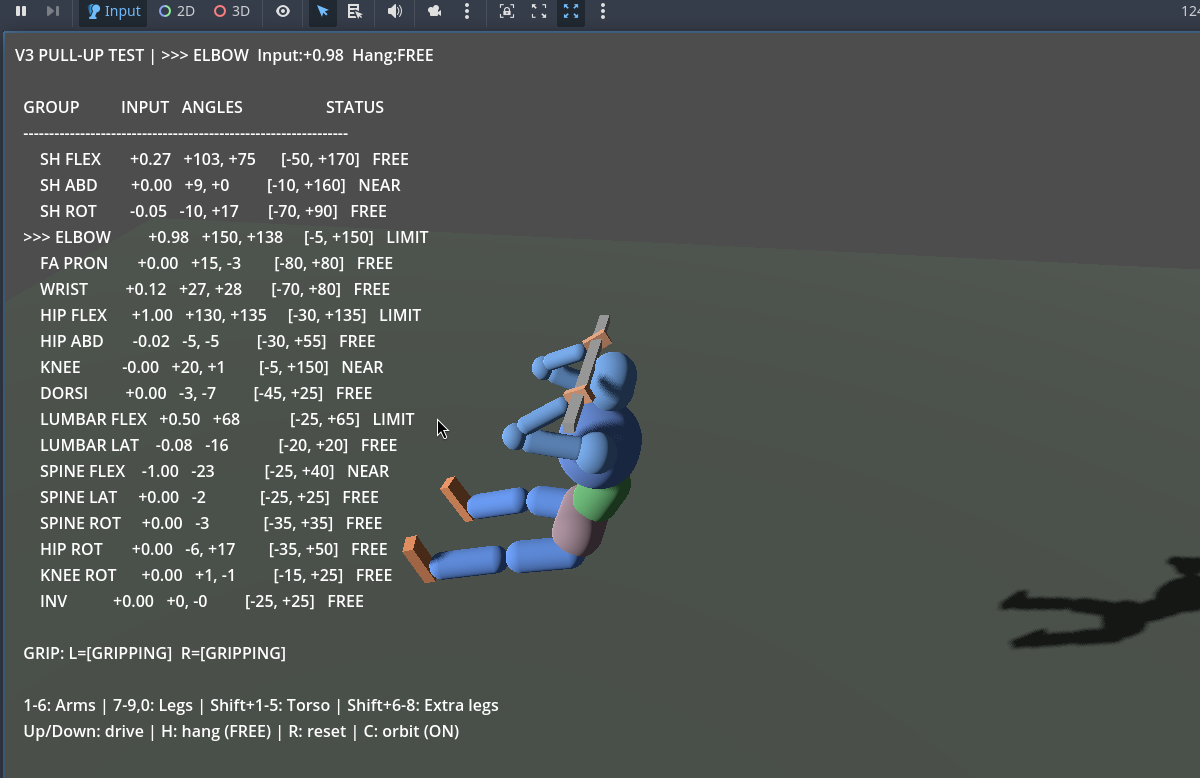
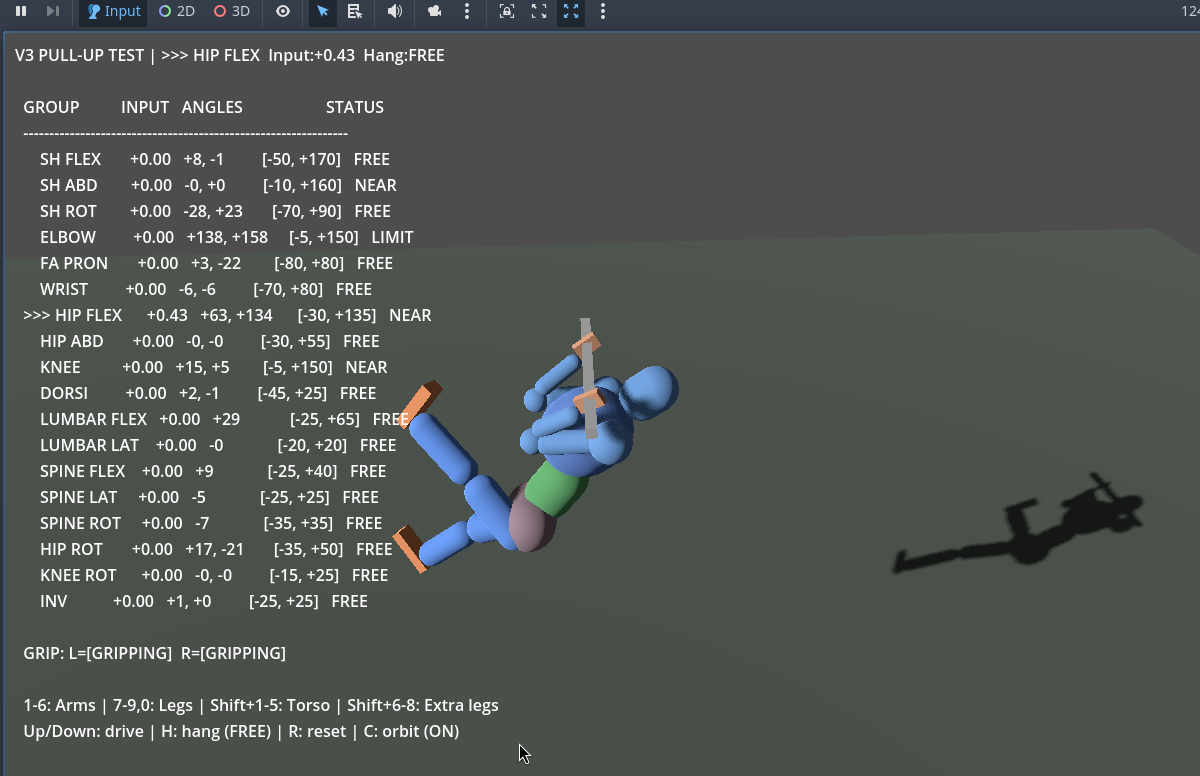
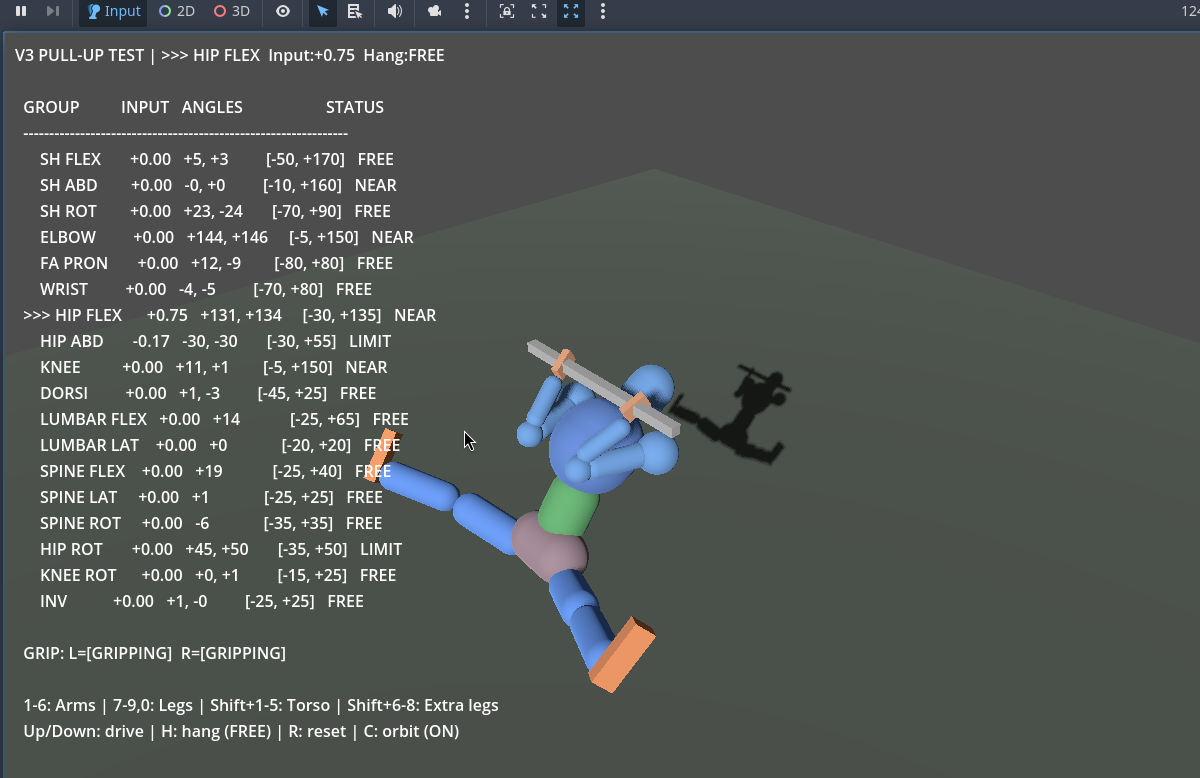
The pull-up test - verifying joint limits and range of motion under load.
Training Infrastructure
The platform is designed for rapid iteration on RL experiments:
- 256 parallel environments in a single Godot instance, each running an independent biped with its own treadmill and physics
- 8x time acceleration - ~640 samples/sec throughput on a GTX 1080 Ti (every bit of VRAM accounted for)
- Modular reward system - 18 separate components (velocity tracking, posture, foot clearance, energy efficiency, gait symmetry, etc.) each individually weighted and toggleable
- Curriculum framework - continuous difficulty ramps for belt speed, harness force, direction constraints. Not discrete stages - smooth progressions that bridge skill gaps
- Checkpoint system with milestone archival - every significant training run documented with reward configuration, TensorBoard data, and behavioral notes
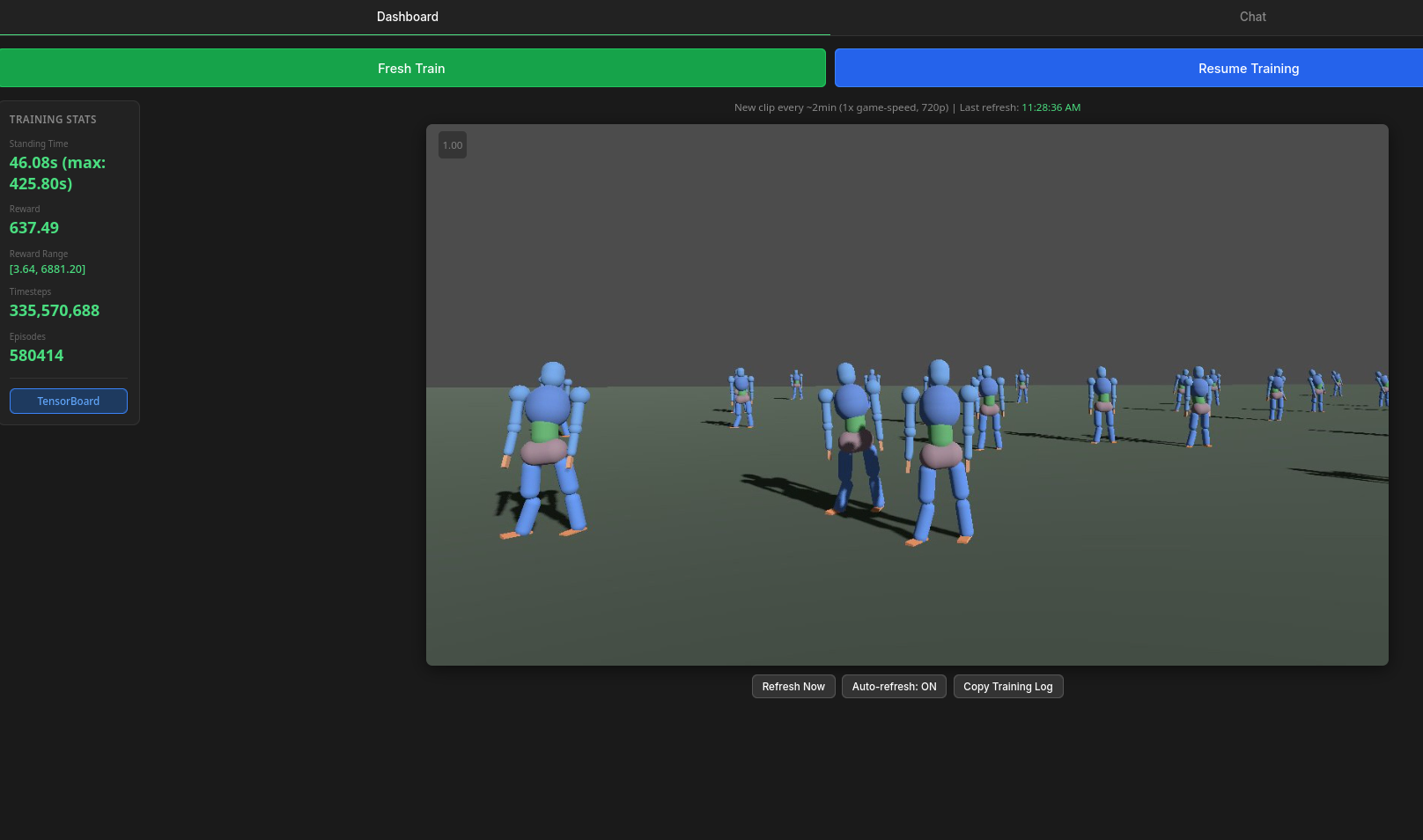
Remote Monitoring
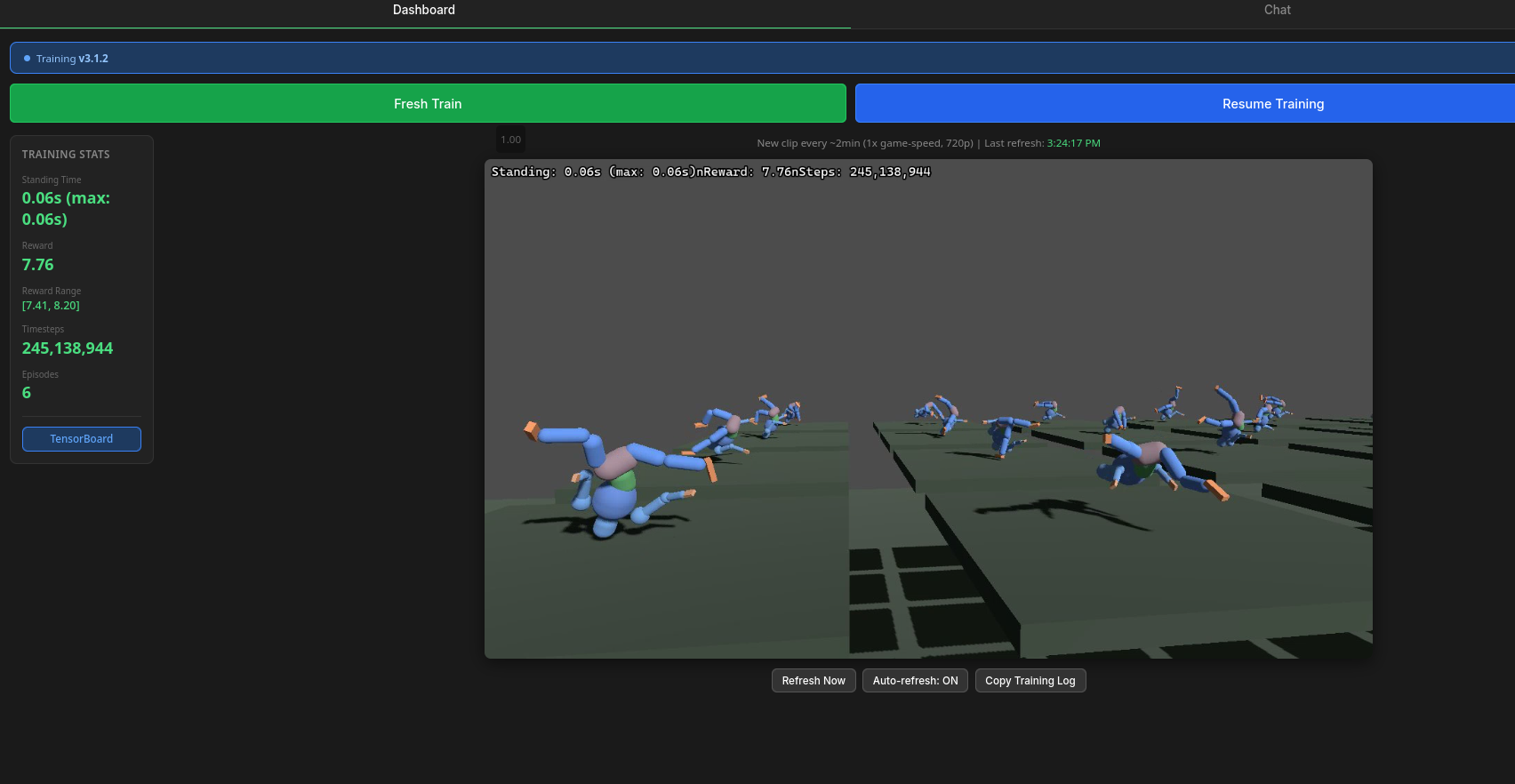
The training monitor - great for catching the exact moment things start going sideways.
The dashboard runs on a Flask server accessible remotely via Tailscale:
- Live MJPEG video stream from the training environment - watch bipeds learn (or fail) in real time
- Training statistics - mean standing time, episode reward, steps per second
- Control panel - start fresh runs, resume from checkpoints, stop training
- Direct TensorBoard link - reward curves, value loss, policy loss, explained variance, entropy
This matters because RL training runs are long. Being able to glance at the video feed from my phone and see whether the biped is shuffling, standing, vibrating, or actually stepping - that's the difference between catching a reward hacking exploit in 10 minutes vs. wasting 8 hours of GPU time.
The Reward Landscape
The most interesting part of this project isn't the code. It's the reward engineering.
Training a 31-DOF humanoid to walk from scratch means designing a reward function that:
- Rewards forward movement without allowing shuffling
- Maintains posture without preventing weight transfer
- Encourages stepping without destabilizing the torso
- Penalizes energy waste without suppressing necessary movement
Each of the 18 reward components addresses a specific failure mode discovered during training. The weights are DOF-group-aware: torso joints get heavy stillness penalties (should stay quiet), ankles get light ones (need freedom for balance corrections), and primary movers are somewhere in between.
Papers & Techniques Implemented
-
PPO (Proximal Policy Optimization) - core training algorithm via Stable Baselines3
-
Curriculum learning - progressive difficulty scaling inspired by locomotion literature
-
Contact-phase reward design - gait cycle rewards rather than trajectory prescription
-
DOF-group-weighted penalties - biomechanically-informed reward shaping
-
Treadmill + harness training - environmental curriculum forcing progression beyond standing equilibria
-
Categorical Policies (Islam & Huber 2025) - replaced the standard Gaussian policy with a latent categorical that selects among multiple behavior modes. Promising idea for multimodal exploration in high-DOF control, but produced worse results than vanilla PPO on this rig
Referenced but not yet implemented: DeepMimic (Peng et al. 2018), AMP/ASE (Peng et al. 2021-22), motor synergy architectures, frontier expansion learning.
Key Discoveries
- Reward hacking is creative: The biped discovered it could fall backward onto its feet and "surf" on contact to accumulate reward. Added torso-below-hips termination to close the exploit.
- Local optima are robust: Both the shuffle plateau (128M steps) and standing plateau (245M steps) required environmental changes - not just reward tweaks - to escape.
- Curriculum beats pure reward shaping: The treadmill environment forced progression that no amount of reward tuning could achieve from static ground.
- DOF-weighted penalties are essential: Uniform stillness penalties suppress necessary movement. Different joint groups have different biomechanical roles.
- The Python/SB3 bottleneck is real: 256 parallel environments saturate the training pipeline, not the physics engine. Room to scale further with faster RL frameworks.
Stack
Godot 4.5, Python 3, PyTorch, Stable Baselines3, Flask, TensorBoard, ONNX, Tailscale
All of this ran on a GTX 1080 Ti. 256 parallel physics environments, PPO training, and a live MJPEG monitoring stream - every bit of VRAM accounted for. It worked, but the card was not happy about it.
Status & Roadmap
500M+ training steps across multiple milestones. Stable standing achieved. Treadmill training with curriculum in progress for emergent stepping.
The staged progression: locomotion > terrain navigation > balance recovery > striking > self-play combat - all on the same rig and policy architecture.